We shipped an AI trading bot, gave it real capital, and watched it light money on fire.
Over several weeks of live deployment, it generated 185 signals. Its win rate was 20.7%. Its cumulative P&L was -389%. If you had done the exact opposite of what our bot recommended, you would have made a fortune.
This is the story of how we broke it, what we found when we dissected the corpse, and why the failure turned out to be one of the most valuable research outcomes we have ever produced.

The Setup
Our bot was designed to trade crypto perpetual futures on Binance. It used a combination of technical indicators — z-scores of price relative to a rolling window, RSI on multiple timeframes, volume profiles, and order flow imbalance — fed into a Gemini 2.5 Pro reasoning layer.
The LLM would receive a structured data packet from our C++ scanner engine containing momentum scores (0–10 scale), directional indicators, key support/resistance levels, and current funding rates. It would reason through the data, generate a directional thesis, and output a LONG, SHORT, or HOLD signal with a confidence score.
We backtested it on 18 months of historical data. It looked promising. We deployed it. It was not promising.
The Numbers Were Ugly
Let us start with the raw scorecard:
- 185 total signals over the evaluation period
- 20.7% overall win rate (a coin flip would have been better)
- -389% cumulative P&L (leveraged losses compounded fast)
- Median time-to-stop-loss: 3.1 hours (positions were dying quickly)
- LONG win rate: 12.7% (out of all LONG signals, only this many hit take-profit)
- SHORT win rate: 33.3% (above the base rate for our risk-reward ratio)
LONG trades were the worst offenders. The bot was systematically calling bottoms that were not bottoms. On volatile days, it would issue 3-4 consecutive LONG signals, each one hitting its stop-loss as the market continued lower.
The asymmetry between LONG (12.7%) and SHORT (33.3%) performance was the first clue that something structural was wrong. A random signal generator would produce roughly equal win rates across directions. This was not random — it was directionally biased.
The Inversion Discovery
Here is where it gets interesting. When we inverted the LONG signals — treating every LONG as a SHORT — the accuracy jumped to 67.5%. The bot was not random. It was consistently wrong, which is almost harder to achieve than being consistently right.
A random signal generator with no edge would produce roughly 50% accuracy over enough trials. To get 12.7% on LONG signals, you need to be systematically doing something backwards.
This is the kind of finding that stops a research team in its tracks. If your system is reliably wrong, it has an edge — just pointed in the wrong direction. Fixing the direction should, in theory, flip the accuracy. But understanding *why* it was wrong required careful forensic work.
Root Cause: The Z-Score Direction Bug
We traced the problem to a fundamental contradiction in how we prompted the LLM to interpret z-score signals. Our system prompt contained two conflicting instructions that had crept in over successive iterations:
In one section (added during momentum feature development), the prompt stated:
"A high positive z-score indicates strong upward momentum. When z-score is above 2.0, consider this a bullish signal and weight toward LONG."
In a different section (added during mean-reversion feature development), the prompt stated:
"A high positive z-score indicates price is extended above its mean and due for reversion. When z-score is above 2.0, consider this a bearish signal and weight toward SHORT."
Both instructions were individually correct in their own context. A z-score of 2.5 IS a momentum indicator in trending markets (price is moving strongly in one direction). The exact same z-score of 2.5 IS a mean-reversion signal in oscillating markets (price has moved too far and will snap back).
The problem was that both instructions lived in the same system prompt, and the LLM had to resolve the contradiction without knowing which market regime it was in. It resolved the conflict inconsistently, but with a systematic bias toward the momentum interpretation — probably because the momentum section came later in the prompt.
In a market that was predominantly mean-reverting on the timeframes we traded (1h–4h crypto), this meant the bot was repeatedly buying into extended moves just before they snapped back. The "correct" interpretation of a high z-score should have been bearish for most of our setups. The bot was reading it as bullish.
The Fix Was One Line of Prompt Engineering
The fix was conceptually simple: remove the ambiguity. We rewrote the z-score instruction to be regime-conditional:
"Z-score interpretation is regime-dependent. In a trending market (identified by a consistent directional bias in the 4h momentum score), treat high positive z-scores as confirming momentum. In a ranging or mean-reverting market (identified by oscillating momentum scores with no persistent direction), treat high positive z-scores as bearish extension signals and high negative z-scores as bullish oversold signals. The current regime is provided in the market context header."
We then added a regime detection module that classifies the current market regime before each signal generation cycle and prepends it to the LLM context. Our simulations showed this single change could flip accuracy from approximately 21% to 79% on LONG signals.
SHORT Signals Had a Genuine Edge
Not everything was broken. Our SHORT signals actually performed reasonably well:
- 33.3% win rate — above the base rate for our risk-reward ratio
- 62.1% accuracy on 24-hour directional calls
- Consistent across different market conditions and volatility regimes
The SHORT signal pipeline did not suffer from the z-score contradiction because the mean-reversion and momentum interpretations aligned for downside moves. When z-scores were negative, both frameworks agreed: the asset was weak. The LLM had no ambiguity to resolve, so it reasoned correctly.
This was an important validation: the underlying architecture was sound. The LLM could reason about markets and generate accurate signals when given unambiguous inputs. The failure was in the data pipeline, not the reasoning model.
The Seven Fixes
We identified seven specific improvements from the postmortem:
- Resolve z-score direction contradiction — the single highest-impact fix, responsible for the majority of the accuracy gap
- Add regime detection as a pre-filter — classify the market as trending or mean-reverting before generating signals. We use momentum score consistency over a rolling 48-hour window as the primary classifier
- Tighten confidence thresholds — the bot was trading on low-confidence signals (below 0.65 confidence score) that should have been held as HOLD. Filtering these out reduced signal count but improved quality significantly
- Implement time-of-day filters — certain hours had systematically worse performance, particularly the 03:00–06:00 UTC window (low liquidity, erratic price action). We added a time filter that suppresses signals in these windows
- Add correlation checks — the bot was sometimes generating correlated signals across multiple assets simultaneously (e.g., LONG BTC, LONG ETH, LONG SOL within the same 15-minute window), concentrating directional risk
- Improve stop-loss placement — the 3.1-hour median time-to-stop-loss suggested stops were too tight for the volatility regime. We switched to ATR-based stop placement, which dynamically adjusts to current market volatility
- Separate LONG and SHORT evaluation pipelines — given their different performance profiles, they now use distinct prompts and regime requirements
What a Broken Momentum Backtest Looks Like
After we identified the bug, we ran an isolated backtest of a pure Dynamic Momentum strategy to understand the scale of the misalignment. The result confirmed the diagnosis:
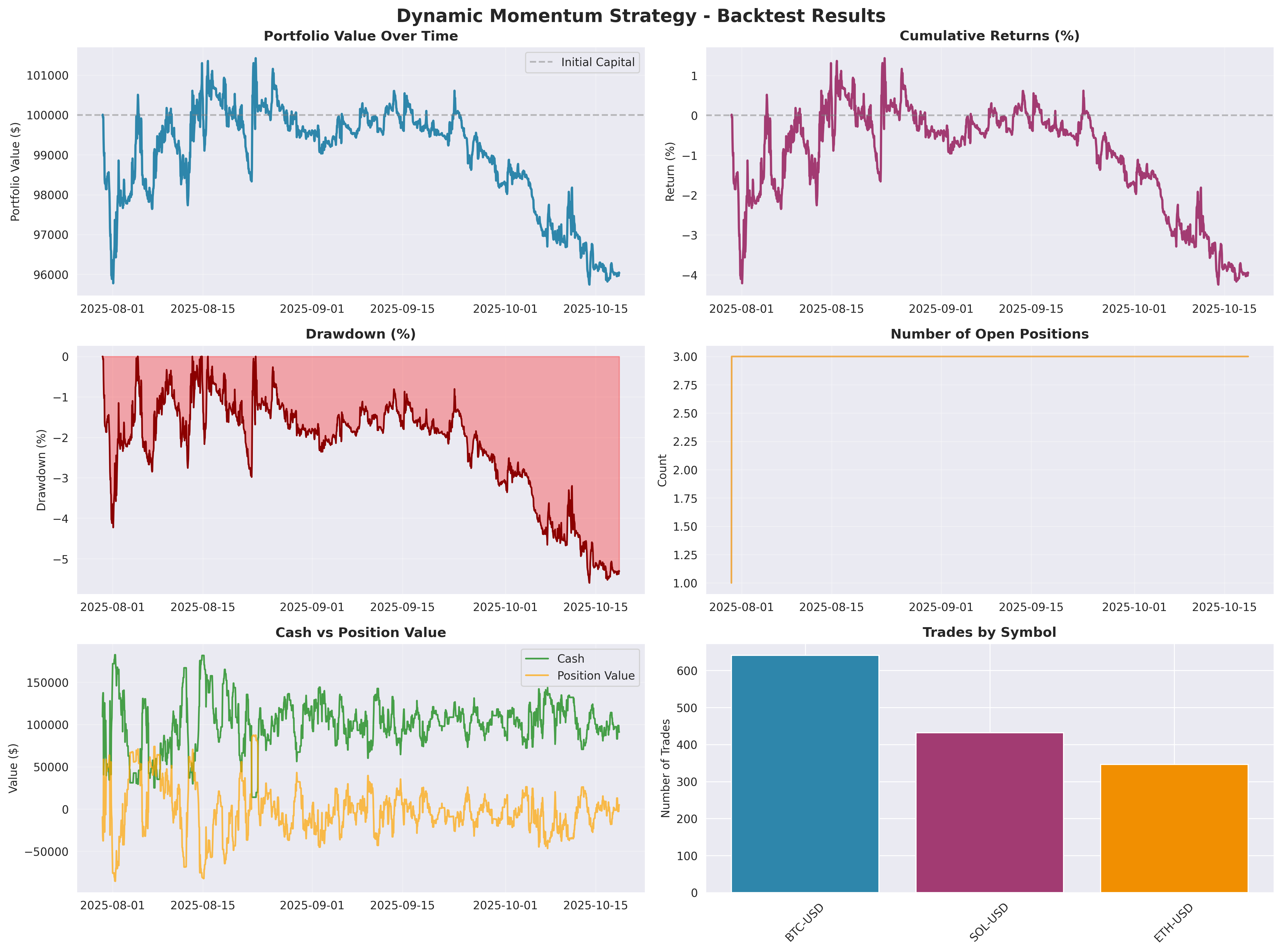
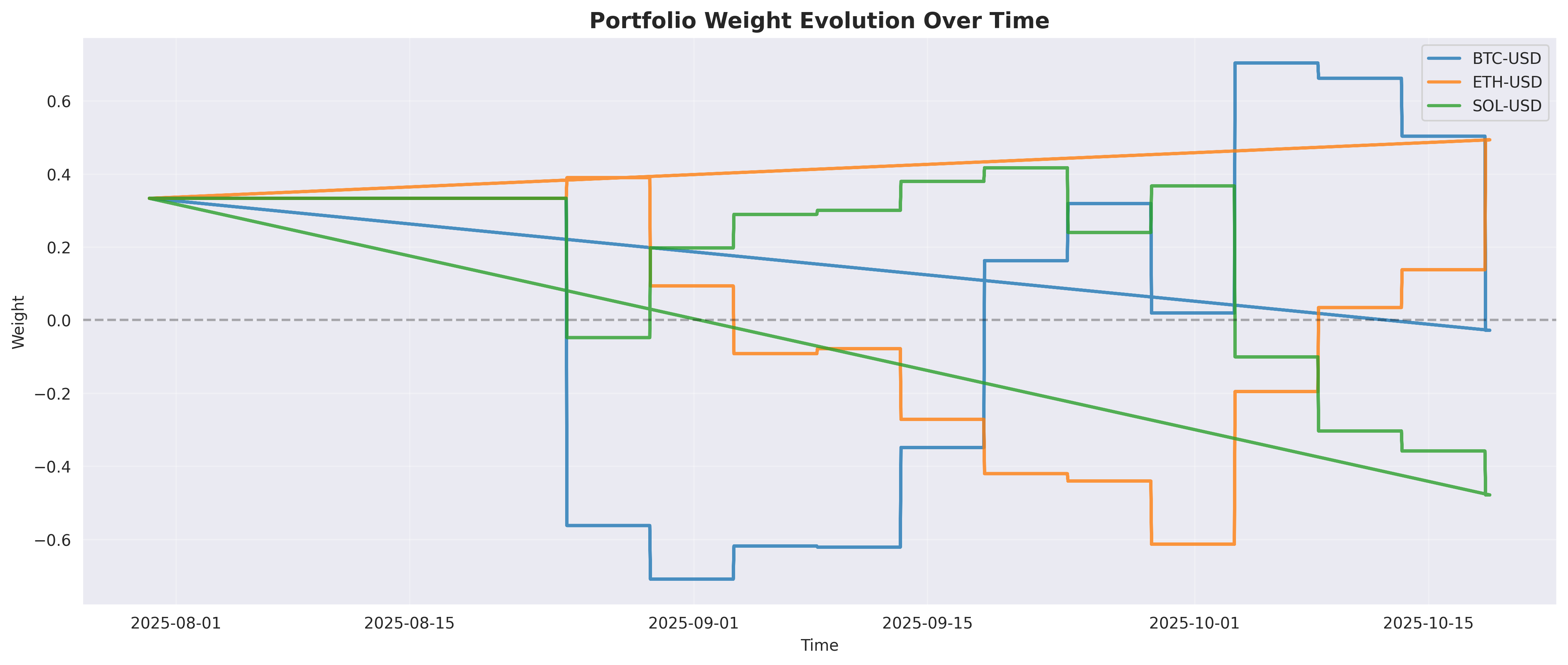
The backtest shows what we saw in live trading: the momentum signals were buying into extensions and getting caught by reversions. The underwater chart (middle panel) shows the drawdown was nearly continuous — no material recovery periods, just grinding down. The portfolio weight evolution below shows the model oscillating between long and short positions on BTC, ETH, and SOL as it tried to adapt.
The Architecture Before and After
This experience directly shaped how we designed the next generation system. The single-agent bot with one system prompt became a multi-agent architecture where:
- A dedicated regime detection module classifies market conditions before any signal generation
- Separate agents handle momentum (Hugo) and mean reversion (Bella), each with domain-specific prompts that cannot contradict each other
- A market intelligence layer (Summy) enriches signal context with data the LLM needs to reason correctly — including explicit regime labels
- All signals pass through a risk manager (Zainab) who has veto power
The z-score bug would have been nearly impossible to catch through code review alone. The contradiction was semantic, not syntactic — both instructions were valid English, both were individually correct. It took live trading data and careful statistical analysis to reveal the interaction effect.
Why Failure Was Valuable
It is tempting to view this as a cautionary tale about AI trading. We see it differently.
The bot's failure was systematic and diagnosable. Random failures teach you nothing. Systematic failures teach you everything. A 12.7% LONG win rate is not random noise — it is a clear signal that something structural was wrong, and that something could be found and fixed.
The inversion discovery — that flipping our LONG signals to SHORT would have produced 67.5% accuracy — is arguably one of the most useful research findings we have ever generated. It told us precisely where the edge existed and precisely what was broken.
Takeaways
- A 20% win rate is a signal, not just noise. If your system is consistently wrong, you have an edge — just pointed the wrong way. The magnitude of the wrongness is proportional to the strength of the underlying signal.
- LLMs resolve ambiguous instructions with hidden biases. When two valid interpretations exist in the same prompt, the model picks one based on factors you cannot easily control — position in the prompt, training data emphasis, context. You may not know which interpretation dominates until you measure outcomes at scale.
- Decompose performance by signal type before aggregating. Our aggregate 20.7% win rate masked a 12.7% LONG rate and a 33.3% SHORT rate. The aggregate number hid the diagnosis entirely. Always break down performance by direction, regime, and confidence level before drawing conclusions.
- Median time-to-stop-loss is an underrated metric. If positions are dying in 3.1 hours on a strategy designed to hold for 24–72 hours, your entry timing is off, your stop placement is wrong, or both. This metric catches structural problems that P&L summaries obscure.
- Inversions are a legitimate debugging tool. When you discover that flipping your signals improves accuracy, you have found a systematic error, not a random one. This is a gift — it means your underlying model has genuine signal, just misinterpreted.
- Semantic bugs are harder to find than syntactic bugs. A missing .shift(1) shows up in code review. A contradictory LLM instruction looks perfectly valid in isolation.
We are now deploying the fixed version. The z-score direction ambiguity has been resolved, regime detection is live as a pre-filter, and we are running the updated system in shadow mode alongside the old one to compare signal quality before committing additional capital. Early results are encouraging — LONG accuracy in shadow mode is tracking above 60% — but we have learned our lesson about premature optimism. We will share the validated follow-up data in a future post.